





With the release of V2A, a ground-breaking technology meant to transform video-to-audio conversion, Google DeepMind has once again made a major advancement in the quickly changing field of artificial intelligence. With its seamless integration of visual data and auditory output, this ground-breaking concept has the potential to revolutionize a number of industries by offering new means of interacting with and understanding video information. Google DeepMind’s V2A promises to usher in a new era of video creation by automatically generating soundtracks that bring silent footage to life.

What is V2A?
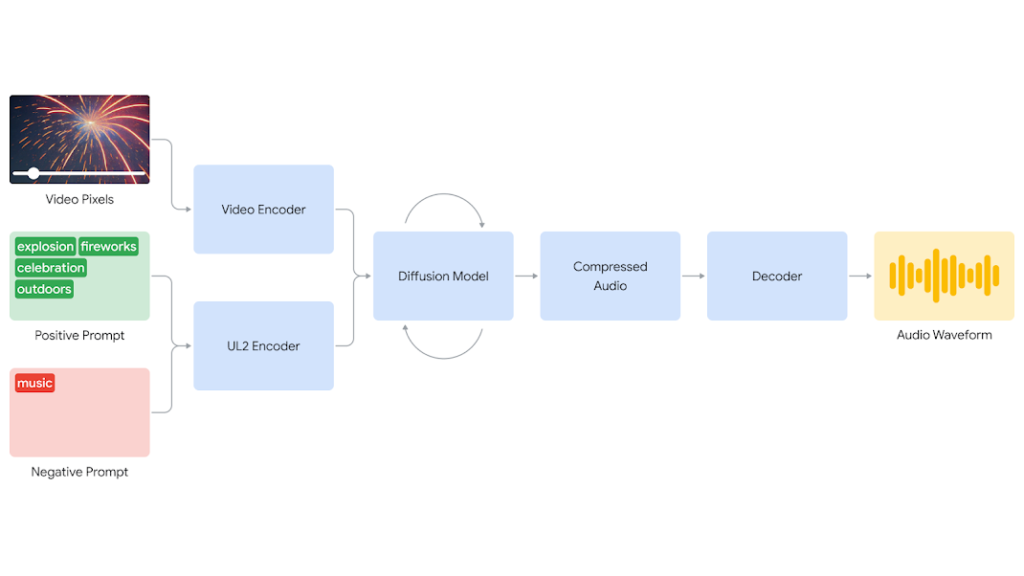
Video-to-Audio, or V2A for short, is a sophisticated artificial intelligence model created by Google DeepMind that transforms visual data from videos into high-fidelity audio. V2A can provide audio that corresponds with the visual information by comprehending and interpreting it. Sound effects, narration, and emotional cues enrich visuals, creating a deeper connection for viewers.
How Does V2A Work?
- Visual Analysis: V2A first analyzes the video frames. It identifies objects, scenes, and motion patterns. Whether it’s a serene sunset or a chaotic cityscape, V2A deciphers the visual context.
- Natural Language Prompts: Next, users provide natural language prompts. These could be descriptions, instructions, or even creative cues. For instance:
- “Add ambient city sounds.”
- “Simulate a bird chirping near the tree.”
- “Imagine a violin playing softly.”
- Audio Synthesis: Armed with visual context and textual prompts, V2A generates audio. It combines pre-existing sound libraries, adapts them to the scene, and creates harmonious auditory experiences. The result? A symphony of realism.
Applications of V2A
- Immersive Videos: Enhance travel vlogs, documentaries, and virtual tours. V2A transports viewers beyond visuals, making them feel the rustling leaves, crashing waves, or distant thunder.
- Creative Storytelling: Filmmakers, animators, and game developers can use V2A to enrich their narratives. Imagine a suspenseful scene with heart-pounding audio cues!
- Accessibility: V2A can significantly enhance accessibility for visually impaired individuals by providing detailed and accurate audio descriptions of visual content, making videos, movies, and other visual media more inclusive.
- Entertainment and Media: In the entertainment industry, V2A can be used to create more immersive experiences by adding high-quality sound effects, background scores, and narrations that are perfectly synchronized with the visual content.
- Education: Educational videos can benefit from V2A by incorporating descriptive audio that explains complex visual information, making learning more effective and accessible to students with different needs.
- Marketing and Advertising: Marketers and advertisers can use V2A to create more engaging and dynamic content by adding audio that complements and enhances visual advertisements, capturing the audience’s attention more effectively.
- Gaming: The gaming industry can leverage V2A to create richer and more immersive gaming experiences by adding real-time audio effects and narrations that respond to in-game actions and scenes.
Key Features of V2A
Visual Understanding: V2A uses state-of-the-art computer vision techniques to analyze and understand visual content in videos. This includes recognizing objects, actions, scenes, and contextual elements within the footage.
Natural Language Processing (NLP): The model leverages advanced NLP to generate accurate and contextually appropriate audio descriptions, narrations, and dialogues that align with the visual content.
Real-Time Conversion: One of the standout features of V2A is its ability to perform real-time video-to-audio conversion, making it ideal for live streaming, real-time captioning, and interactive applications.
Multilingual Capabilities: V2A is designed to support multiple languages, allowing it to generate audio in various languages based on the viewer’s preferences or the video’s requirements.
Emotion and Tone Recognition: The model can detect and replicate emotional tones from visual cues, providing a more immersive and emotionally engaging audio experience.
Challenges and Considerations
- Lip Sync Accuracy: Ensuring precise synchronization between visual and audio elements remains a challenge.
- Multilingual Support: Expanding V2A to handle diverse languages and accents.
- Real-Time Implementation: Can V2A work seamlessly during live broadcasts or video calls?
- Accuracy and Quality: Ensuring the accuracy and quality of the audio generated by V2A is crucial. The model must consistently produce relevant and high-quality audio that accurately reflects the visual content.
- Data Privacy: Handling visual data raises privacy concerns. Ensuring that V2A operates within ethical guidelines and protects user data is paramount.
- Bias and Fairness: Like all AI models, V2A must be carefully trained to avoid biases that could lead to unfair or discriminatory outcomes. Continuous monitoring and updating of the model are necessary to mitigate these risks.
The Future of V2A
V2A from Google DeepMind is a major advancement in artificial intelligence development. Its capacity to smoothly transform visual data into high-quality audio creates new opportunities for creativity and problem-solving in a variety of industries. Continued research promises further refinement of V2A, unlocking new applications across various fields. The launch of V2A is evidence of the quick development of artificial intelligence (AI) technology and its potential to change our world completely. Ethical considerations are vital alongside AI progress. We must ensure responsible use to maximize benefits.
Conclusion
By converting video footage into rich, contextual audio, Google DeepMind’s V2A is poised to completely redefine how we engage with it. This technology opens the door for new applications in marketing, education, entertainment, and other fields in addition to improving accessibility and user experience. In the future, voice-to-audio (V2A) technology will play a crucial role in fusing audio and visual data, enhancing the dynamic and captivating nature of human interactions with digital media.
TO LEARN MORE ABOUT AI CLICK BELOW
- Meta Unveils Five Groundbreaking AI Models
- AI Revolutionizes Cancer Care
- Luma Dream Machine AI
- The Future of Traffic Signal Systems With AI
- Generative AI: Creativity with Machine Learning
- The OpenAI Controversy: Unraveling the Mystery of Q-Star AI
- Embracing the Future of Artificial Intelligence – Krutrim AI
- G-Assist: NVIDIA’s Gaming Assistance
- BrainBridge: Pioneering the Future of Head Transplants
- Neuralink: Bridging the gap between brain and computer

Frequently Asked Questions (FAQs)
V2A stands for Video-to-Audio. It’s an AI system developed by Google DeepMind that generates realistic audio based on visual input.
The process involves analyzing video frames, understanding visual context, and synthesizing audio using natural language prompts.
Immersive Videos: V2A enhances travel vlogs, documentaries, and virtual tours by adding realistic audio.
Accessibility: It benefits the visually impaired by providing descriptive audio alongside videos.
Creative Storytelling: Filmmakers and game developers can use V2A to enrich narratives.
Lip Sync Accuracy: Ensuring precise synchronization between visual and audio elements.
Multilingual Support: Expanding V2A to handle diverse languages and accents.
Real-Time Implementation: Can V2A work seamlessly during live broadcasts or video calls?
As V2A evolves, we’ll experience more captivating audiovisual content.
Currently, the quality of the generated audio depends on the quality of the video input. Additionally, perfect lip-syncing for dialogue remains a challenge.
V2A can generate a wide range of audio, including music, sound effects, and even dialogue (though lip-syncing is still under development).